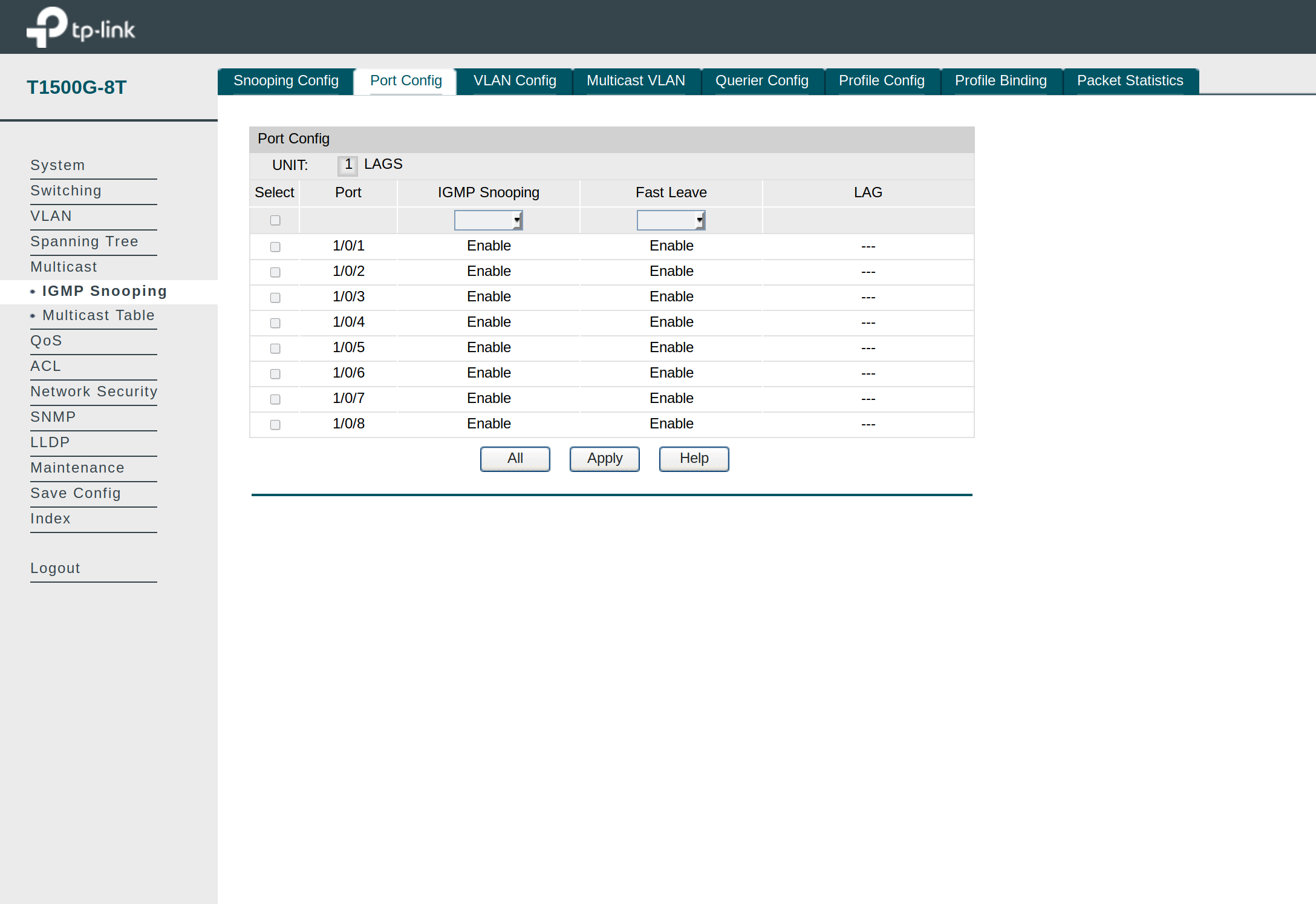
Pypicloud ist für kleine Entwicklerteams oder auch als privater Python-Pakethoster eine interessante alternative, wenn da nur der Overhead nicht wäre. Er kann jedoch leicht in Azure in der PaaS-Umgebung App Service aufgesetzt werden.
Azure App Service
Azure App Service ist eine verwaltete Umgebung zum Aufsetzen von Webanwendungen. Es gibt ihn in verschiedenen Varianten, und Pypicloud benötigt eine Python-Umgebung. Diese wird in Azure als Linux-Container unterstützt.
In diesem Artikel wird mit einfachen Mitteln Pypicloud als App Service eingerichtet. Über Grundlagen wissen von Azure und Azure CLI hinaus wird keine weitere Erfahrung benötigt, insbesondere wird kein Docker-Container konfiguriert.
Voraussetzungen
Alle Befehle müssen von der Kommandozeile ausgeführt werden und können der Reihe nach wie im Artikel eingetippt werden. Alle einzutippenden Befehle beginnen mit $.
Sämtliche Befehle werden aus einem Arbeitsverzeichnis ausgeführt. Der komplette Inhalt dieses Verzeichnisses wird nach Azure hochgeladen.
Als Arbeitsverzeichnis wird ~/pypicloud-test genutzt.
$ mkdir ~/pypicloud-test $ cd ~/pypicloud-test
Azure
Azure CLI muss installiert werden.
Das gezeigte Beispiel verwendet den kostenlosen Tarif für Webanwendungen (F1). Es ist zumindestens ein Probeabbonement für Azure notwendig.
Python
Im folgenden wird davon ausgegangen, dass entweder das System-Python oder ein pyenv genutzt wird. Pthon 3.7.x muss installiert sein. Alternativ kann die Konfigurationsdatei natürlich auch in einem venv erstellt werden und in das Arbeitsverzeichnis kopiert werden.
Pypicloud
Die Pypicloud-Dokumentation beschreibt als Einführung wie Pypicloud sehr schnell lokal gestartet werden kann. Es wird dafür eine virtuelle Python-Umgebung genutzt. Für das Hosting in Azure wird das nicht benötigt, sondern nur die erstellte Konfigurationsdatei.
Das folgende Beispiel zeigt, wie eine Konfiguration für Produktions-Einsatz erstellt werden kann:
$ pyenv shell 3.7.3 $ pip install pypicloud==1.0.15 $ ppc-make-config -p pypicloud-prod.ini [1] s3 [2] gcs [3] filesystem Where do you want to store your packages? 3 Admin username? pypicloud-admin Password: Password: Config file written to 'pypicloud-prod.ini'
Azure App Service
Um eine Python-Webanwendung in App Service laufen zu lassen, müssen sämtliche notwendigen Python-Pakete als requirements.txt gespeichert werden. Die Pakete werden dann im App Service mit pip installiert.
Für Pypicloud wird nur ein Paket benötigt, alle Abghängigkeiten werden von pip automatisch aufgelöst. Die requirements.txt, muss nur eine Zeile enthalten und Pypicloud und die Versionsnummer spezifizieren:
pypicloud==1.0.15Starten der Webanwendung mit Azure
Die Webanwendung kann so bereits gestartet werden. Im Folgenden wird keine Resourcen-Gruppe eingestellt, weitere Beispiele und Konfigurationsmöglichkeiten stehen zum Beispiel in der Azure-Dokumentation.
$ az webapp up --sku F1 -n pypicloud-nerdpause -l westeurope
webapp pypicloud-nerdpause doesn't exist
Creating Resource group 'Nerdpause_rg_Linux_westeurope' ...
Resource group creation complete
Creating AppServicePlan 'Nerdpause_asp_Linux_westeurope_0' ...
Creating webapp 'pypicloud-nerdpause' ...
Configuring default logging for the app, if not already enabled
Creating zip with contents of dir /home/nerdpause/pypicloud ...
Getting scm site credentials for zip deployment
Starting zip deployment. This operation can take a while to complete ...
Deployment endpoint responded with status code 202
You can launch the app at http://pypicloud-nerdpause.azurewebsites.net
{
"URL": "http://pypicloud-nerdpause.azurewebsites.net",
"appserviceplan": "Nerdpause_asp_Linux_westeurope_0",
"location": "westeurope",
"name": "pypicloud-nerdpause",
"os": "Linux",
"resourcegroup": "Nerdpause_rg_Linux_westeurope",
"runtime_version": "python|3.7",
"runtime_version_detected": "-",
"sku": "FREE",
"src_path": "//home//nerdpause//pypicloud"
}Die Ausgabe bestätigt, dass der Server unter http://pypicloud-nerdpause.azurewebsites.net erreichbar ist. Ein kurzer Test zeigt jedoch, dass zwar eine Webanwendung existiert, aber nur die von Azure bereitgestellte Standardseite. Pypicloud ist jedoch nicht gestartet worden.

Aktivieren von Pypicloud
Dies liegt daran, dass Azure beim Start der Webanwendung standardmäßig versucht, bestimmte Webfrontends (zur Zeit Flask und Django) zu erkennen und zu starten, Pypicloud basiert jedoch auf pyramid. In einem Blog-Post wird zwar bestätigt, dass auf pyramid basierende Webapps unterstützt werden, die angegebene Quelle zeigt jedoch nur, dass Gunicorn verwendet wird um Webanwendungen zu starten.
Zum Glück lassen sich pyramid-Anwendungen leicht mit Gunicorn starten. Für die oben angegebene Pypicloud-Konfiguration zum Beispiel so:
$ gunicorn --paste pypicloud-prod.ini
Nun muss nur noch den Azure App Service konfiguriert werden um einen benutzerdefinierten Startbefehl zu verwenden. Dazu muss die der Azure Web Service entsprechend konfiguriert werden:
$ az webapp config set --name pypicloud-nerdpause --resource-group Nerdpause_rg_Linux_westeurope --startup-file 'gunicorn --bind=0.0.0.0 --timeout 600 --paste pypicloud-prod.ini' { ... "appCommandLine": "gunicorn --bind=0.0.0.0 --timeout 600 --paste pypicloud-prod.ini", ... }
Nach kurzer Zeit kann die Webseite neu geladen werden. Es dauert ein bisschen, bis die aktualisierte Konfiguration deployt ist. Leider ist das Ergebnis nicht wie gewünscht, sondern eine Fehlermeldung wird angezeigt.
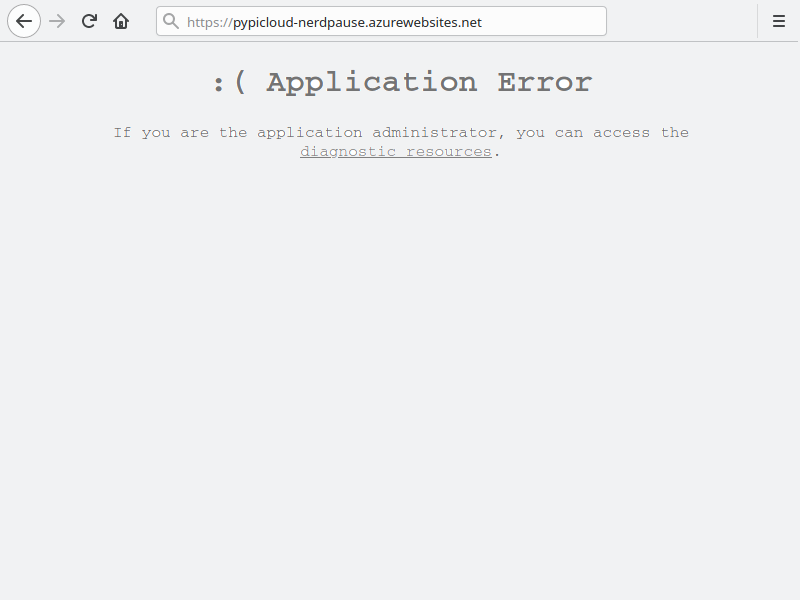
Cache-Datenbank
Die Ursache des Problems ist der Speicher: Das Rootverzeichnis der Webanwendung ist ein gemountetes Azure Files-Verzeichnis. SQLite kann keine Locks erstellen, so dass der Starten des App Service fehlschlägt (sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) database is locked ). Glücklicherweise bestätigt die Pypicloud-Dokumentation, dass die Cache-Datenbank nicht persistiert werden muss:
The cache does not have to be backed up because it is only a local cache of data that is permanently stored in the storage backend
https://pypicloud.readthedocs.io/en/latest/topics/cache.html#cache
Es gibt nun zwei Lösungsmöglichkeiten: Die Datenbank kann einfach an einem anderen Ort gespeichert werden, zum Beispiel im Temp-Verzeichnis. Der Pfad wird als Parameer db.url im Format für SQLAlchemy festgeleg. Dazu muss pypicloud-prod.ini einfach wie folgt angepasst werden:
db.url = sqlite:////tmp/db.sqlite
Alternativ kann die Datenbank im Journal-Modus WAL erstellt werden. Diese kann lokal erstellt und dann zum Webserver geschickt werden:
$ apt install sqlite # optional $ sqlite3 db.sqlite 'pragma journal__mode=wal;' $ az webapp up
Das Ergebnis ist aber immer noch nicht wie erwartet. Die Fehlermeldung verschwindet zwar, es wird jedoch stattdessen eine leere Seite angezeigt. Dies kann mehrere Ursachen haben, z.B. falls Scripte verboten sind.
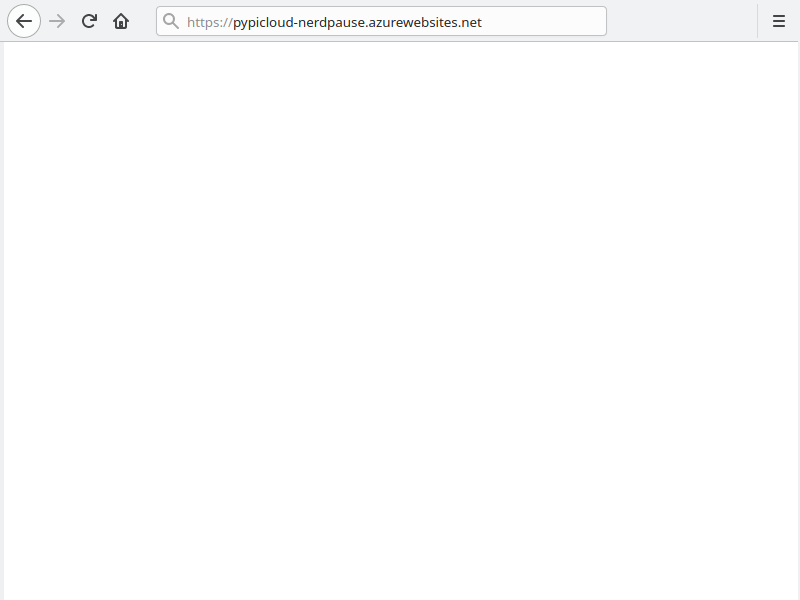
Sichere Verbindungen
Eine genauere Betrachtung der ausgelieferten Seite zeigt jedoch, dass der Quellcode und alle Dateien verfügbar sind. Das Problem ist, das standardmäßig alle Links das http-Protokol nutzen, Azure App Service jedoch https nutzt. Um das zu korrigieren muss pypicloud-prod.ini angepasst werden:
[app:main] filter-with = proxy-prefix [filter:proxy-prefix] use = egg:PasteDeploy#prefix scheme = https
Nun ist der Server bereit 
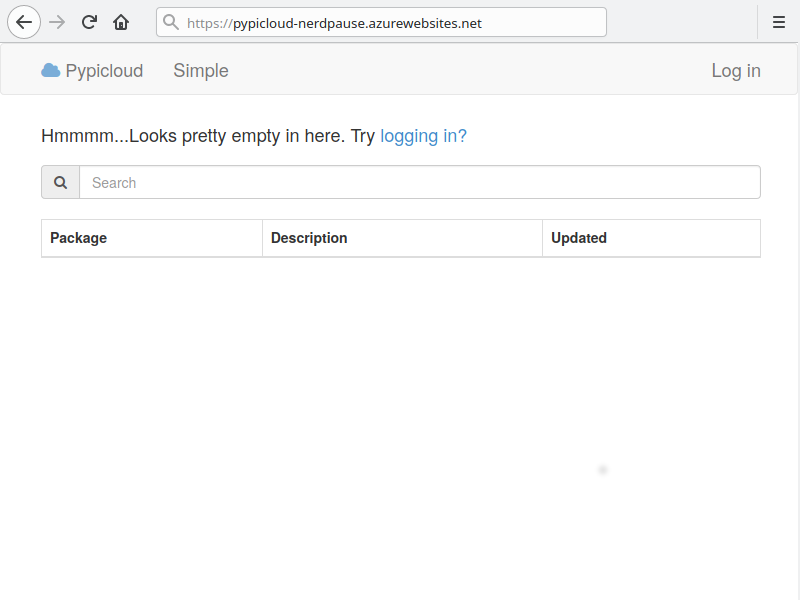
Aber Achtung: Der Service ist ohne weitere Konfiguration weltweit verfügbar und jeder kann darauf zugreifen
Weitere Schritte
Das gezeigte Beispiel ist natürlich erst der Anfang um einen (semi-)professionellen Pypicloud-Server aufzusetzen. Es bieten sich weitere Schritte an.
Daten Persistieren
Der freie Account hat nicht allzu viel Speicher, und die Persistenz ist nur gegeben, solange der Service nicht gestoppt wird (az webapp delete). In diesem Fall sind alle Daten gelöscht.
Die Lösung dazu wäre, die Daten auf einem dafür angelegten Storage-Account zu persistieren.
Automatische Deployments
Anstatt manuell mit Azure CLI kann der Service automatisch aufgesetzt werden z.B. mit Terraform.






 Auf jeden Fall habe ich das hier mal aufgeschrieben.
Auf jeden Fall habe ich das hier mal aufgeschrieben.
 ) Die Umsetzung ist aber etwas umständlich. Zunächst benötigt man einen eigenen Service
) Die Umsetzung ist aber etwas umständlich. Zunächst benötigt man einen eigenen Service















 ich hatte das gleiche Problem bereits mit Thunderbird, das den Profilordner nicht ordnungsgemäß lädt, wenn er einen symbolischen Link enthält.
ich hatte das gleiche Problem bereits mit Thunderbird, das den Profilordner nicht ordnungsgemäß lädt, wenn er einen symbolischen Link enthält.